Main Page
Welcome to GraphIT
This project at the University of Regensburg investigates how dependency graphs can be used to model courses, curricula, and personal learning progress. The initial focus lies on courses in higher education. This prototype is built on Wikibase, the knowledge-graph platform powering Wikidata.
Here's a dependency graph of all learning content currently in the prototype. Please scroll down to learn more.
Dive Right In
| Quick_Overview | |
|---|---|
| This page gives you a quick overview of the project, its structure and how you can use it. | 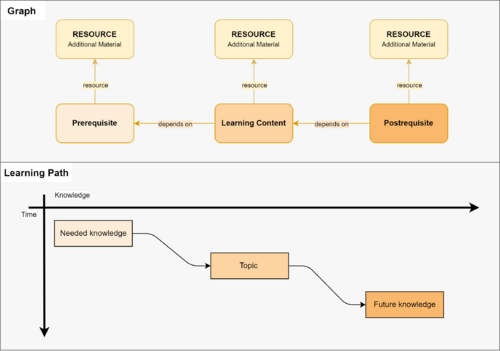
|
| GraphStructure | |
|---|---|
| This page contains a detailed documentation of the graph structure and how it is used to organize the graph using diagrams and example queries. |
|



| Feature_Demo | |
|---|---|
| This page gives a couple of examples of what the graph can do. | |
Why GraphIT?
What should students learn? Which topics should be covered in a given course of study? These are difficult questions:
The more the knowledge of mankind grows, the more specialized the courses need to be that a university offers. Of course, specialized courses can no longer cover the same breadth of knowledge as classical courses of study. Therefore, we need to constantly redefine what the essential core of a subject is.
On the other hand, in a networked world, interdisciplinary courses of study are valuable. In these, we can no longer teach knowledge and competencies of the parent subjects in the same depth, but must redefine which of these are absolutely necessary for the study goal.
At the same time, students' prior knowledge is becoming more and more heterogeneous due to more open educational pathways and opportunities for digital learning. Also, their goals and opportunities differ a lot. A "one-size-fits-all" degree program will do less and less justice to these students. Instead, we need to find ways to support students in their individual learning goals and speeds while providing them with guidance, support, and education.
Our processes for developing curricula and courses no longer meet these complex and ever-changing demands. Manual labor and gut instinct still prevail in the organization of studies and the development of curricula.
Basic Concept
In the GraphIT project, we develop a dependency graph of learning content. Each node in the graph represents a learning content (or topic) . An edge in the graph indicates which further topics build on the current topic (i.e., depend on it).
Such a graph can structure the content of a single course, a curriculum, a discipline, a university, or the whole world (in theory :) ).
For any given topic, the necessary prerequisites can be retrieved from the graph. When open educational resources (OER) or examinations get linked to every topic, students get a flexible tool for self-study and self-assessment.
Applications
Envisioned applications:
Educators
- collect topics and build curricula and course syllabi.
- identify central and irrelevant topics by looking at the graph.
- attach OER and other resources to topics and re-use these
- create optimal paths through a curriculum, i.e. identify which topics should be taught in which order
- monitor students' progress and identify bottlenecks, i.e. topics where many students struggle
- ...
Students
- follow a pre-defined or custom path through a set of topics
- find out what the best path to learning a certain skill is
- track own achievements and compare to individual goals or others
- find new, interesting things one can learn with the knowlede one already has
- ...
(Do you have further suggestions? Please tell us via Discord or email!)
Questions and Challenges
There are quite a few obvious and less obvious challenges and open questions. The goal of the GraphIT project is to explore these questions by implementing a prototype and evaluating it in practice.
- Can this concept really work?
- How large should a topic be in order to be both useful an managable?
- Learning is more complex than just 'checking off' topics that one has learned. How do we include repetitions, different grades of learning (c.f. Bloom's taxonomy), or 'soft skills' in such a graph?
- How could one use this graph?
- Which tools are needed in order to efficiently work with a really large graph? (We are developing these at the moment)
- Can intelligent tools (AI!) help with managing, modifying, and updating a large graph?
- Which visualizations and aggregations of the graph are most helpful?
- How can people from different disciplines and institutions, and with different viewpoints collaborate within one large graph?
- Should there be one large graph or many small ones?
- How can we build a platform that is as open and flexible as possible while still maintaining consistency and protecting personal data?
Status and Roadmap
As of June 2023, we are finalizing our infrastructure, building up a prototype graph, and developing experimental tools for working with graphs.
Previously, we discussed the concept with a few people, developed a prototype (also using Wikibase) that we scrapped again, and researched related projects.
About / Contact
This is a project by the Physical Digital Affordances Group / Chair of Media Informatics at the University of Regensburg
Primary contact: Raphael Wimmer (email)
Current Contributors: Alexander Weichart, Leonie Schrod
You can also find us on the GraphIT Discord server
The project is supported by a small grant from the Bavarian State Ministry for Science and the Arts via the Center for University and Academic Teaching (ZHW) at the University of Regensburg.